Before diving in, if you need help, guidance, or want to ask questions, join our Community and a member of the Marqo team will be there to help.
1. What are Multimodal Models?
Multimodal models are a class of machine learning models that can process and integrate information from multiple modalities or types of data. Unlike traditional models that handle a single type of input (e.g., text or image), multimodal models can simultaneously handle and learn from different types of inputs such as text, images, audio, and more. Pretty cool!
.png)
These models are significant because they mirror how humans perceive and process information. For example, when we look at an image, we often also consider contextual text (like a caption) to fully understand the image's content. Multimodal models aim to bring this level of understanding to artificial intelligence, enabling more sophisticated and contextually aware applications.
2. What is CLIP Model?
CLIP (Contrastive Language-Image Pre-training) is a multimodal model developed by OpenAI that can understand and relate images and textual descriptions in a unified manner. CLIP was introduced in early 2021 [1] and represents a significant advancement in the field of multimodal learning.
.png)
CLIP stands out because it was trained to directly understand the relationship between images and the natural language descriptions associated with them. An example of this can be seen in the Figure above where we have an image of Marqo’s logo with the caption ‘Marqo logo’. This enables CLIP to perform a variety of tasks including zero-shot classification, image search, and captioning.
3. How Does CLIP Work?
CLIP uses a unique approach to learn the relationship between images and text. In this section we’ll break down the fundamental aspects of CLIP to truly understand how it works.
i. Data Collection
As with any machine learning model, data is essential…and the more, the better! CLIP was trained on a large dataset of 400 million image-text pairs collected from the internet. This diverse dataset ensured that the model could generalize well to a wide range of concepts and scenarios.
The example used in the original CLIP paper [1] was an image of a dog with the caption ‘Pepper the aussie pup’. Of course, in the Figure below you can see this example as well as others behind it.
.png)
Awesome, so we’ve seen what data we’re dealing with. Let’s take a look at how we can transform this data in machine readable format.
ii. Dual Encoder Architecture
As we’ve established in our previous articles on sentence embeddings and image embeddings. Encoders are needed to translate these into a fixed-dimensional vector or embedding. You’d be right in thinking that because we have both text and images here, we’ll need both a text and image encoder respectively.
CLIP employs these two separate encoders:
- Text Encoder: This encoder processes text descriptions and converts them into a fixed-dimensional feature vector. The text encoder is usually based on a Transformer architecture similar to those used in language models like BERT.
- Image Encoder: This encoder processes images and converts them into a fixed-dimensional feature vector. The image encoder is typically a Vision Transformer (ViT).
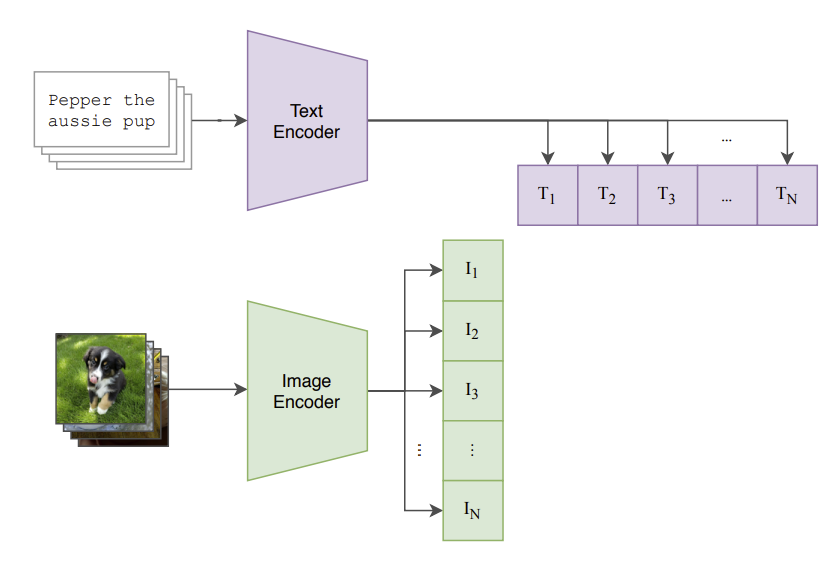
Now we have the ability to generate vector embeddings for both our text and images. How do we train our model to understand these pairs? That’s where contrastive learning plays a vital role.
iii. Contrastive Learning
The core of CLIP's training process is contrastive learning. The goal is to bring the feature vectors of matching image-text pairs closer together in the embedding space while pushing the vectors of non-matching pairs further apart.
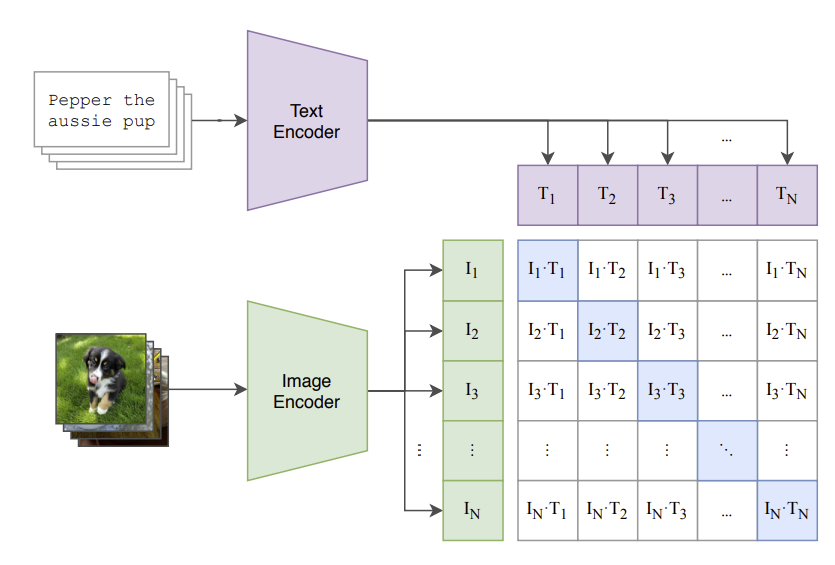
This is achieved through a contrastive loss function. For each image-text pair in a training batch, CLIP computes the cosine similarity between all possible image and text feature vectors. The model then maximizes the similarity for correct pairs and minimizes it for incorrect pairs. This process trains the model to align images with their corresponding textual descriptions effectively.
The key outcome of this is that you get a dual embedding. So, you can understand:
- Images with language
- Language with images
- Images with images
- Language with language.
Super powerful!
iv. Zero-Shot Learning
Once trained, CLIP can perform various tasks without additional fine-tuning. This capability is known as zero-shot learning. A dataset classifier is created from label text and this is used for zero-shot prediction as seen in the Figure below:
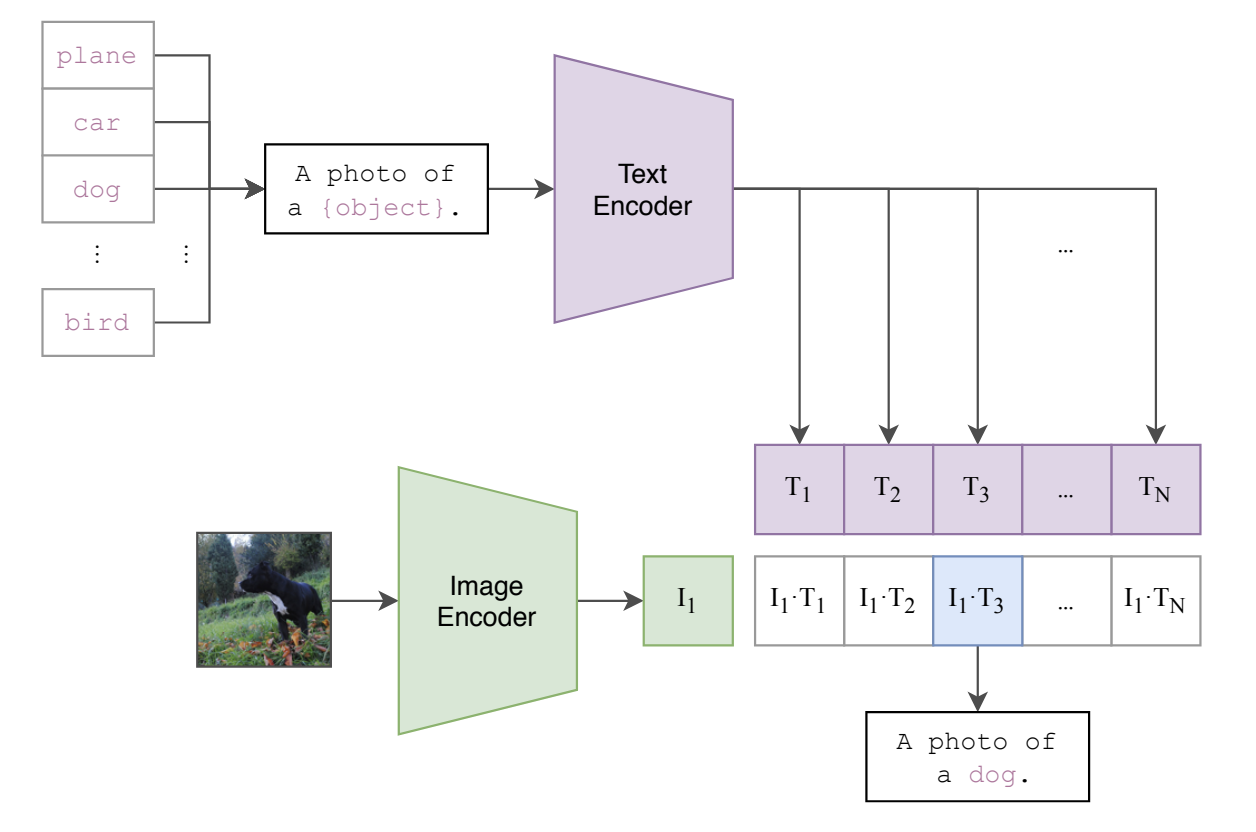
Awesome! By leveraging CLIP's ability to understand and relate images and text through contrastive learning, we can achieve tasks such as zero-shot classification, image search and retrieval, and generating textual descriptions for images, all without needing task-specific fine-tuning. This opens up new possibilities for creating more intuitive and versatile AI systems that can seamlessly integrate and process multimodal information.
Let’s take a look at CLIP in action!
4. Programming with CLIP
Let’s look at the power of CLIP through a simple programming example.
For this article, we will be using Google Colab (it’s free!). If you are new to Google Colab, you can follow this guide on getting set up - it’s super easy! For this module, you can find the notebook on Google Colab here or on GitHub here. As always, if you face any issues, join our Slack Community and a member of our team will help!
We will take three different images of cats from Unsplash. Let’s display these.
.png)
We now process the captions and images as follows:
All that’s left to do is get the predictions and display the results! Let’s get the predictions first.
Now we can display the images with their corresponding, predicted captions.
These are the results:
.png)
Pretty cool!
5. Limitations of CLIP
As you’ll know in machine learning, not all models are perfect and so CLIP does come with its limitations.
- CLIP's zero-shot performance is limited in fine-grained classification tasks, such as differentiating models of cars, species of flower and variants of aircraft
- CLIP struggles with abstract tasks like counting the number of objects in an image
- CLIP struggles with novel tasks such as estimating the distance to the nearest car in a photo
With these limitations, we ask ourselves, can we extend CLIP to accommodate for more complex and realistic data scenarios?
6. Generalised Contrastive Learning (GCL)
Generalized Contrastive Learning (GCL) is a framework developed and researched by our team here at Marqo, that extends the principles of CLIP to accommodate more complex and realistic data scenarios [2]. Unlike CLIP, which primarily focuses on learning relationships between images and single text descriptions, GCL generalizes the training process to include any number of text and image pairs when representing documents. Additionally, GCL incorporates relevance (or rank) information to improve the first stage of retrieval processes.
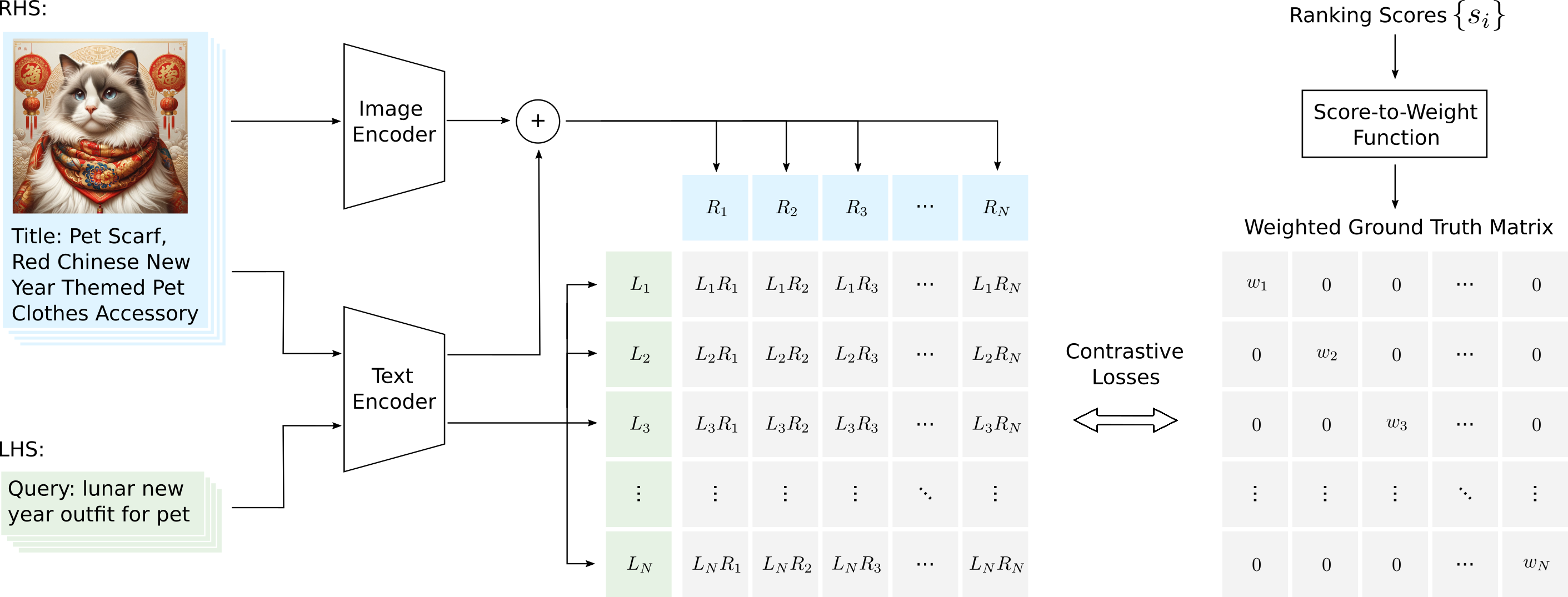
For example, consider a query like "lunar new year outfit for pet." This query might correspond to a document with a title like "Pet Scarf, Red Chinese New Year Themed Pet Clothes Accessory" and an image of the pet scarf. GCL can learn the relationship between the query and this document, with a weight indicating how relevant the document is based on historical user interactions, such as clicks or purchases. By training on multiple types of data, GCL creates more comprehensive embeddings that better represent the documents. This approach improves the ranking and retrieval of documents by directly optimizing for relevance and incorporating various data sources into the training process.
Awesome! Let’s take a look at it in action.
7. Programming with GCL
First, we install the relevant modules:
Now, let's take an image of a pair of Oxford shoes and display it below.
This returns:

Now, let's take this image along with three captions:
- “A dog”
- “Vintage Style Women's Oxfords”
- “A cat”
The idea is that we will use GCL to generate scores for each of these captions when compared to the image. We will expect captions 1 and 3 to be low as, indeed, the image is not a picture of a cat or dog. Caption 2 will hopefully have the highest score as they are indeed, Oxford shoes. However, they are men’s shoes and not necessarily vintage. This is something GCL will be able to pick up on and so we expect a higher score compared to captions 1 and 3.
Let’s see what we get!
This returns:
Awesome, we get the results:
Pretty cool! If you want to try out GCL for yourself, visit our repository here with more information.
8. Conclusion
Multimodal models like CLIP represent a significant step forward in creating AI systems that can understand and interact with the world more like humans do. By integrating and learning from multiple types of data, these models can perform a wide range of tasks with greater accuracy and flexibility. Models like Marqo’s GCL extend CLIP to accommodate for more complex and realistic data scenarios.
9. References
[1] A. Radford, et al. Learning Transferable Visual Models From Natural Language Supervision (2021)
[2] T. Zhu, M. Jung and J. Clark. Generalized Contrastive Learning for Multi-Modal Retrieval and Ranking (2024)





